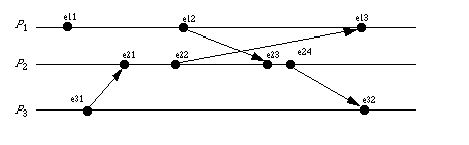
Lamport's clocks keep a virtual time among distributed systems. The goal is to provide an ordering upon events within the system.
Assume all clocks start at 0, and d is 1 (that is, each event incrememts the clock by 1). At event e12, C1(e12) = 2. Event e12 is the sending of a message to P2. When P2 receives the message (event e23), its clock C2 = 2. The clock is reset to 3. Event e24 is P2's sending a message to P3. That message is received at e32. C3 is 1 (as one event has passed). By rule 2, C3 is reset to the maximum of C2(e24)+1 and the current value of C3, so C3 becomes 5.
Clearly, if a -> b, then C(a) < C(b). But if C(a) < C(b), does a -> b?
The answer, surprisingly, is not necessarily. In the above example, C3(e31) = 1 < 2 = C1(e12). But e31 and e12 are causally unrelated; that is, e31 ->X e12. However, C1(e11) < C3(e32), and clearly e11 -> e32. Hence one cannot say one way or the other.
This is based upon Lamport's clocks, but each process keeps track of what is believes the other processes' interrnal clocks are (hence the name, vector clocks). The goal is to provide an ordering upon events within the system.
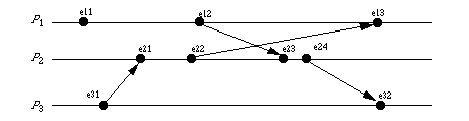
Here is the progression of time for the three processes:
e11: C1 = (1, 0, 0)
e31: C3 = (0, 0, 1)
e21: C2 = (0, 0, 1) as ta = C3(e31) = (0, 0, 1) and previously, C3 was (0, 0, 1)
e22: C2 = (0, 1, 1)
e12: C1 = (2, 0, 0)
e23: C2 = (2, 1, 1) as ta = C1(e12) = (2, 0, 0) and previously, C2 was (0, 1, 1)
e24: C2 = (2, 2, 1)
e13: C1 = (2, 1, 1) as ta = C2(e22) = (0, 1, 1) and previously, C1 was (2, 0, 0)
e32: C3 = (2, 2, 1) as ta = C2(e24) = (2, 2, 1) and previously, C3 was (0, 0, 1)
Notice that C1(e11) < C3(e32), so e11 -> e32, but C1(e11) and C3(e31) are incomparable, so e11 and e31 are concurrent.
The goal of this protocol is to preserve ordering in the sending of messages. For example, if send(m1) -> send(m2), then for all processes that receive both m1 and m2, receive(m1) -> receive(m2). The basic idea is that m2 is not given to the process until m1 is given. This means a buffer is needed for pending deliveries. Also, each message has an associated vector that contains information for the recipient to determine if another message preceded it. Also, we shall assume all messages are broadcast. Clocks are updated only when messages are sent.
Pi sends a message to Pj
Pj receives a message from Pi
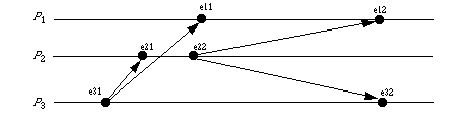
Here is the protocol applied to the above situation:
e31: P3 sends message a; C3 = (0, 0, 1); ta = (0, 0, 1)
e21: P2 receives message a. As C2 = (0, 0, 0), C2[3] = ta[3] - 1 = 1 - 1 = 0 and
C2[1] => ta[1] and C2[2] => ta[2] = 0. So the message is accepted,
and C2 is set to (0, 0, 1)
e11: P1 receives message a. As C1 = (0, 0, 0), C1[3] = ta[3] - 1 = 1 - 1 = 0 and
C1[1] => ta[1] and C1[2] => ta[2] = 0. So the message is accepted,
and C1 is set to (0, 0, 1)
e22: P2 sends message b; C2 = (0, 1, 1); tb = (0, 1, 1)
e12: P1 receives message b. As C1 = (0, 0, 1), C1[2] = tb[2] - 1 = 1- 1 = 0 and
C1[1] => tb[1] and C1[3] => tb[2] = 0. So the message is accepted,
and C1 is set to (0, 1, 1)
e32: P3 receives message b. As C3 = (0, 0, 1), C3[2] = tb[2] - 1 = 1 - 1 = 1 and
C1[1] => tb[1] and C1[3] => tb[2] = 0. So the message is accepted,
and C3 is set to (0, 1, 1)
Now, suppose ta arrived as event e12, and tb as event e11. Then the progression of time in P1 goes like this:
e11: P1 receives message b. As C1 = (0, 0, 0), C1[2] = tb[2] - 1 = 1 - 1
= 0 and C1[1] => tb[1], but C1[3] < tb[3], so the message is
held until another message arrives. The vector clock updating algorithm
is not run.
e12: P1 receives message a. As C1 = (0, 0, 0), C1[3] = ta[3] - 1 = 1 - 1
= 0, C1[1] => ta[1], and C1[2] => ta[2]. The message is
accepted and C1 is set to (0, 0, 1). Now the queue is checked. As C1[2]
= tb[2] - 1 = 1 - 1 = 0, C1[1] => tb[1], and C1[3] => tb[3],
that message is accepted and C1 is set to (0, 1, 1).
The goal of this protocol is to ensure that messages are given to the receiving processes in order of sending. Unlike the Birman-Schiper-Stephenson protocol, it does not require using broadcast messages. Each message has an associated vector that contains information for the recipient to determine if another message preceded it. Clocks are updated only when messages are sent.
Pi sends a message to Pj
Pj receives a message from Pi
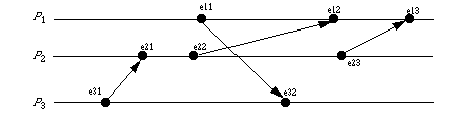
Here is the protocol applied to the above situation:
e31: P3 sends message a to P2.
C3 = (0, 0, 1); ta = (0, 0, 1),
Va = (?, ?, ?); V3 = (?, (0, 0, 1), ?)
e21: P2 receives message a from P1.
As Va[2] is uninitialized, the
message is accepted. V2 is set to (?, ?, ?)
and C2 is set to (0, 0, 1).
e22: P2 sends message b to P1.
C2 = (0, 1, 1); tb = (0, 1, 1),
Vb = (?, ?, ?); V2 = ((0, 1, 1), ?, ?)
e11: P1 sends message c to P3.
C1 = (1, 0, 0); tc = (1, 0, 0),
Vc = (?, ?, ?); V1 = (?, ?, (1, 0, 0))
e12: P1 receives message b from P2.
As Vb[1] is uninitialized, the
message is accepted. V1 is set to (?, ?, ?)
and C1 is set to (1, 1, 1).
e32: P3 receives message c from P1.
As Vc[3] is uninitialized, the
message is accepted. V3 is set to (?, ?, ?)
and C3 is set to (1, 0, 1).
e23: P2 sends message d to P1.
C2 = (0, 2, 1); td = (0, 2, 1),
Vd = ((0, 1, 1), ?, ?); V2 = ((0, 2, 1), ?, (0, 0, 1))
e13: P1 receives message d from P2.
As Vd[1] < C1[1], so the message
is accepted. V1 is set to ((0, 1, 1), ?, ?)
and C1 is set to (1, 2, 1).
Now, suppose tb arrived as event e13, and td as event e12. Then the progression in P1 goes like this:
e12: P1 receives message d
from P2.
But Vd[1] = (0, 1, 1) <X (1, 0, 0) = C3,
so the message is queued for later delivery.
e13: P1 receives message b from P2.
As Vb[1] is uninitialized,
the message is accepted. V1 is set to (?, ?, ?) and C1 is set to (1, 1, 1).
The message on the queue is now checked. As
Vd[1] = (0, 1, 1) < (1, 1, 1) = C1,
the message is now accepted. V1 is set to ((0, 1, 1), ?, ?)
and C1 is set to (1, 2, 1).
The goal of this distributed algorithm is to capture a consistent global state. It assumes all communication channels are FIFO. It uses a distinguished message called a marker to start the algorithm.
Pi sends marker
Pi receives marker from Pj

Here, all processes are connected by communications channels Cij. Messages being sent over the channels are represented by arrows between the processes.
Snapshot s1:
P1 records LS1, sends markers on C12 and C13
P2 receives marker from P1 on C12; it records its state LS2, records state of C12 as empty, and sends markers on C21 and C23.
P3 receives marker from P1 on C13; it records its state LS3, records state of C13 as empty, and sends markers on C31 and C32.
P1 receives marker from P2 on C21; as LS1 is recorded, it records the state of C21 as empty.
P1 receives marker from P3 on C31; as LS1 is recorded, it records the state of C31 as empty.
P2 receives marker from P3 on C32; as LS2 is recorded, it records the state of C32 as empty.
P3 receives marker from P2 on C23; as LS3 is recorded, it records the state of C23 as empty.
Snapshot s2: now a message is in transit on C12 and C21.
P1 records LS1, sends markers on C12 and C13
P2 receives marker from P1 on C12 after the message from P1 arrives; it records its state LS2,
records state of C12 as empty, and sends marker on C21 and C23
P3 receives marker from P1 on C13; it records its state LS3, records state of C13
as empty, and sends markers on C31 and C32.
P1 receives marker from P2 on C21; as LS1 is recorded, and a message has arrived
since LS1 was recorded, it records the state of C21 as containing that message.
P1 receives marker from P3 on C31; as LS1 is recorded, it records the state of C31 as empty.
P2 receives marker from P3 on C32; as LS2 is recorded, it records the state of C32 as empty.
P3 receives marker from P2 on C23; as LS3 is recorded, it records the state of C23 as empty.
The goal of this protocol is to detect when a distributed computation terminates.
Pi sends a computation message to Pj
Pj receives a computation message B(W) from Pi
Pi becomes idle
Pi receives a control message C(W)
The picture shows a process P0, designated the
controlling agent, with
W0 = 1. It asks P1 and
P2 to do some computation.
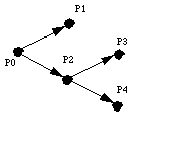 It sets W1 to 0.2, W2 to 0.3, and
W3 to 0.5. P2 in turn asks
P3 and P4
to do some computations. It sets W3 to 0.1 and
W4 to 0.1.
It sets W1 to 0.2, W2 to 0.3, and
W3 to 0.5. P2 in turn asks
P3 and P4
to do some computations. It sets W3 to 0.1 and
W4 to 0.1.
When P3 terminates, it sends C(W3) = C(0.1) to P2, which changes W2 to 0.1 + 0.1 = 0.2.
When P2 terminates, it sends C(W2) = C(0.2) to P0, which changes W0 to 0.5 + 0.2 = 0.7.
When P4 terminates, it sends C(W4) = C(0.1) to P0, which changes W0 to 0.7 + 0.1 = 0.8.
When P1 terminates, it sends C(W1) = C(0.2) to P0, which changes W0 to 0.8 + 0.2 = 1.
P0 thereupon concludes that the computation is finished.
Total number of messages passed: 8 (one to start each computation, one to return the weight).
 Send email to
cs251@csif.cs.ucdavis.edu.
Send email to
cs251@csif.cs.ucdavis.edu.
Department of Computer Science
University of California at Davis
Davis, CA 95616-8562